Chapter 6 Choosing priors: Part I
![]()
In the previous section, we learned how we can use normal, student t, and various kinds of non-central t likelihoods to model means, mean differences, and effect sizes. But if we actually want to compute Bayes factors then we’ll also need to define priors. While the likelihoods are a model of our data the priors will serve as the models for the hypotheses we actually want to compare.
There are two broad schools of thought when it comes to defining priors. The first is to choose priors that can be used in a wide range of situations and don’t need to be tailored to the specifics of the situation at hand. This is often framed in terms of selecting priors that aren’t dependent on the individual beliefs or theories of a specific researcher, or priors that represent ignorance about any possible effect. These are sometimes called objective, reference, uninformative, or default priors (these terms aren’t exactly synonymous, but for our purposes the technical differences won’t matter).
The second approach is to choose priors that are specific to the situation at hand. This might be by selecting priors that represent actual scientific theories, selecting priors that constrain the predicted effects to be within the expected range, or choosing priors based on, for example, previous evidence about the nature of the effect being studied. These kinds of priors go under the label of informed, or subjective priors. It is also important to note that the lines between the two approaches is not always clear cut. Rather, they are often blurred.
6.1 Reference, objective, uninformative, and default priors
The most straightforward way to come up with a prior that can work in a wide range of situations is to use the principle of indifference. This is the approach that we used when we were coming up with our very first prior for the coin flip example. Our reasoning was roughly as follows:
If we don’t know what the coin bias is (just that it is some value between 0 and 1), then we have no reason for predicting that any particular outcome (i.e., number of heads after a particular number of flips) will occur more often than any other particular outcome.
If we flip the coin \(n\) times, then there are \(n + 1\) possible outcomes. Therefore, we assign a probability of \(\frac{1}{n+1}\) to each outcome.
The prior that fits with this prediction is a uniform prior from 0 to 1.
The idea here is that in coming up with the prior we’re trying to make as few assumptions as possible. Coming up with priors that make as few assumptions as possible is not always straightforward. There are a number of technical difficulties that can arise when choosing priors that seemingly don’t make any assumptions. Some of these issues arise when, for example, choosing a prior that is non-informative when a question is asked one way (for example, asking about the bias of the coin) but then doesn’t turn out to be non-informative when the question is asked in a different, but equivalent way (for example, asking about the log odds of obtaining heads).
Because of these technical difficulties, people have come up with rules for choosing priors that make as few assumptions as possible. Once such rule if Jeffrey’s rule. A detailed treatment is Jeffrey’s rule is outside the scope of this course, but it is interesting to note that Jeffrey’s rule relies on the realm of possible events (the same thing that caused our worries about p-values being impacted by different sampling rules).
6.2 Default priors for effect sizes
Another method for defining objective priors that has been particularly popular within psychology has been to use default priors. The most prominent example of this approach has been the use of default priors for effect sizes—the so-called default Bayesian t-test (Rouder et al, 2009).
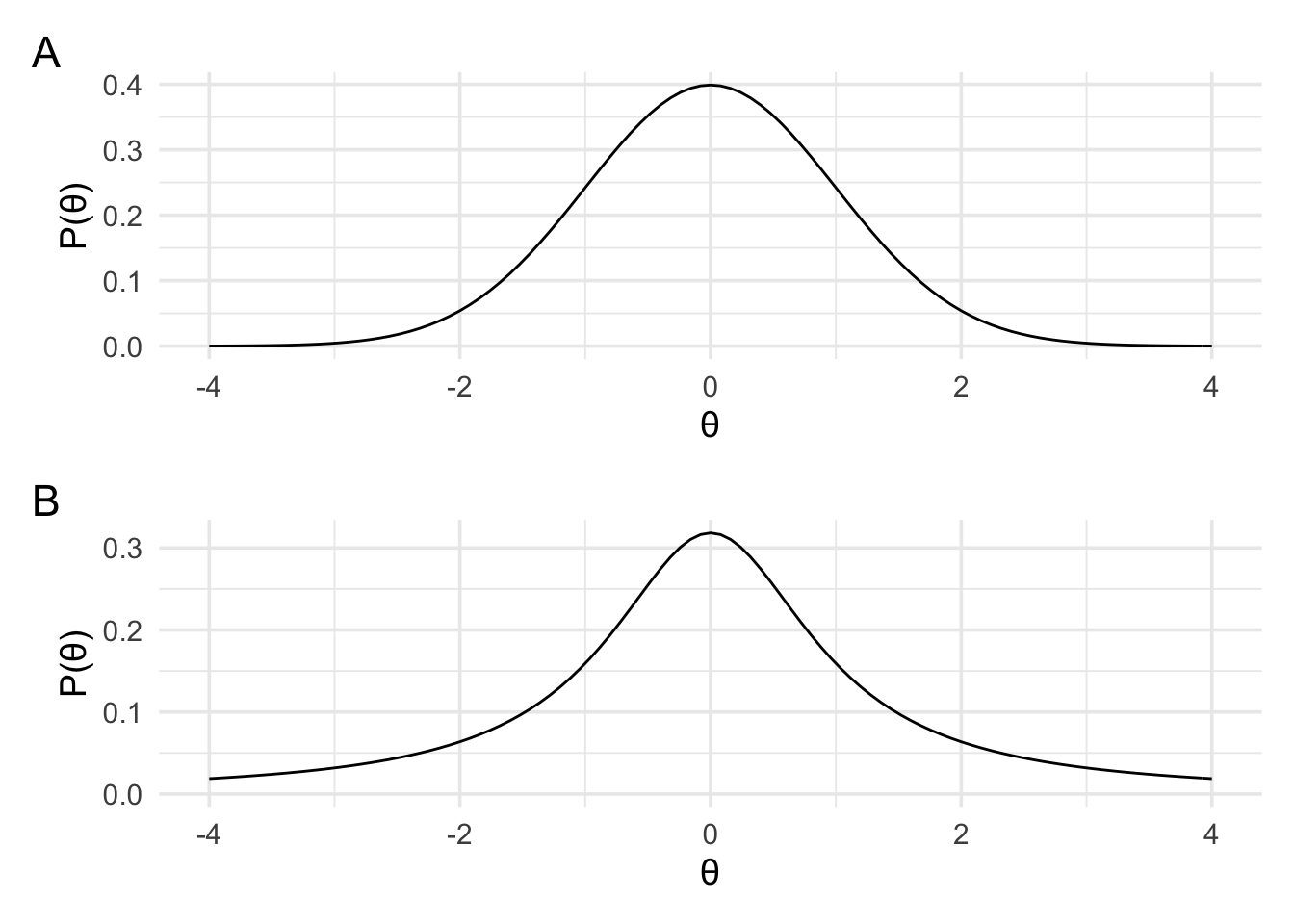
The default Bayesian t-test can be used anywhere where a regular frequentist t-test can be used. For the default Bayes t-test, the data are modelled in terms of the effect size. That is, a non-central d or non-central d2 likelihood is used (depending on whether the data are from one-sample/paired data or independent samples). These are the likelihood’s that we defined near the end of the previous section. However, what really characterises this approach is the prior that is employed. The default Bayes t-test uses a Cauchy prior. A Cauchy distribution is similar in shape to a standard normal distribution (panel A below), however it has far fatter tails (panel B below).
For a more in-depth discussion of Cauchy priors, a recent paper by
Schmalz et al, 2021 is highly
recommended. We’ll learn about them by exploring some of their properties
using bayesplay. As you can see from the plots above, compared to
a normal distribution, the Cauchy has far less mass in the middle of the
distribution. For the Cauchy distribution, 50% of the distribution lies
between -1 and +1 while for the normal distribution 68% of the
distribution lies between -1 and +1.
We can define a Cauchy prior using the prior function from
bayesplay and setting the family to cauchy. Two other values can
also be set. The first is location which determines the centre of the
distribution. This has a default value of 0. The second is scale which
can change how wide or narrow the distribution is. The original paper by
Rouder et al (2009) set this value to 1. However, now a value of
\(\frac{1}{\sqrt{2}}\approx0.707\) is more typical, and this is the default
value in their R package (called BayesFactor).
Let us define a Cauchy prior with a location of 0, and a scale of 1.
standard_cauchy <- prior(
family = "cauchy",
location = 0,
scale = 1
)And now we’ll define a Cauchy prior with a location of 0, and a scale of \(\frac{1}{\sqrt{2}}\).
medium_cauchy <- prior(
family = "cauchy",
location = 0,
scale = 1 / sqrt(2)
)With both priors defined we can plot them above each other.
standard_cauchy_plot <- plot(standard_cauchy) +
theme_minimal(14) +
theme(title = element_text(size = 8)) +
labs(subtitle = "Cauchy(0, 1)")
medium_cauchy_plot <- plot(medium_cauchy) +
theme_minimal(14) +
theme(title = element_text(size = 8)) +
labs(subtitle = "Cauchy(0, 0.707)")
standard_cauchy_plot / medium_cauchy_plot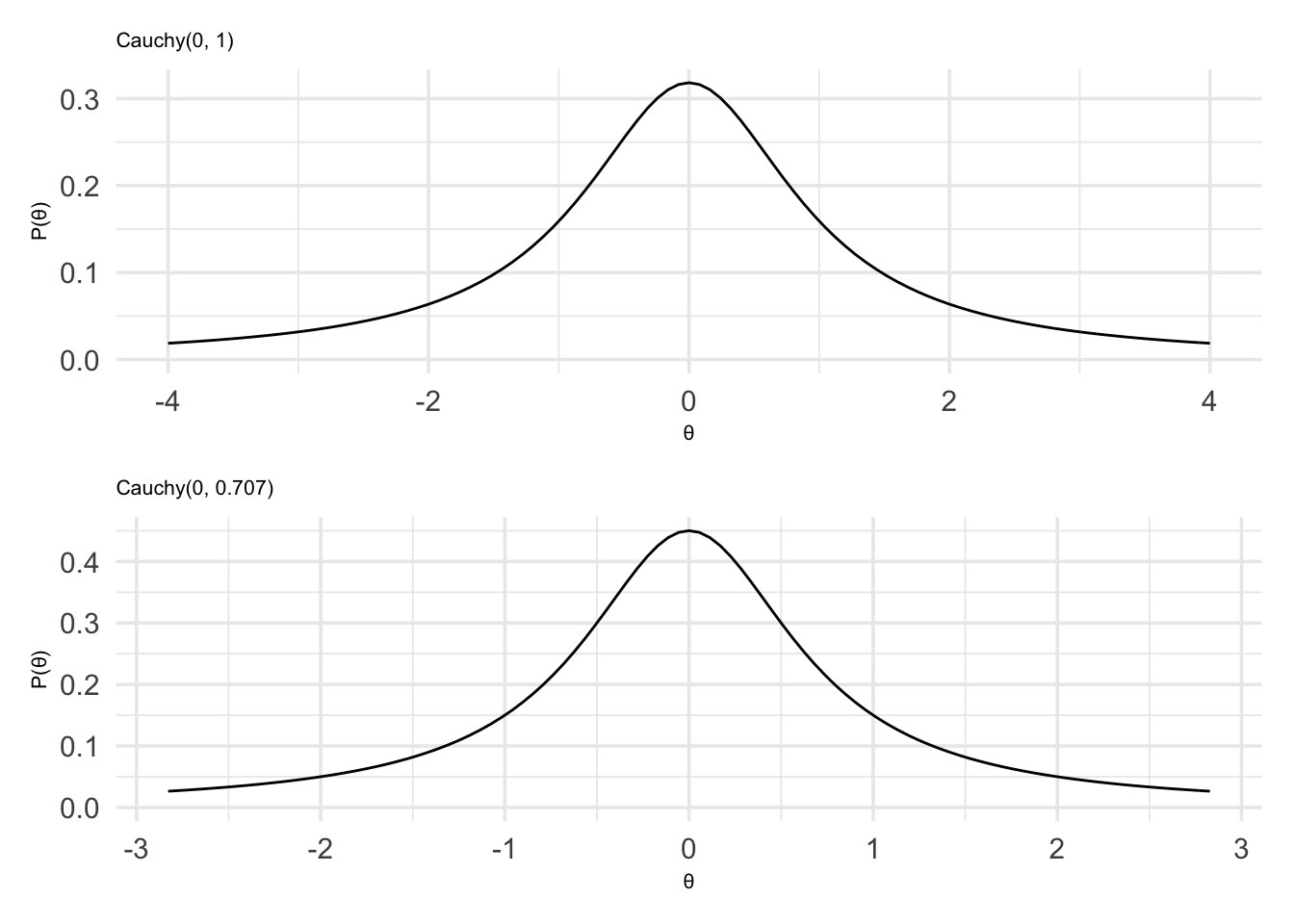
Although the motivation behind the default Bayes t-test is to come up with objective priors, Rouder et al (2009) also note that re-scaling the prior to be wider or narrower, depending on the range of predicted effect sizes, can be a way to tune the prior to the particulars of the experiment. As mentioned earlier, the divide between objective and subjective priors is a blurry one.
One of these Cauchy priors is going to represent our alternative hypotheses, but we also need a prior to represent our null hypothesis. To keep things simple we’ll just use a point hypothesis at zero.
Now that we’ve decided on the priors we’re going to use, we need to get to the most important bit! The data. We’ll analyse the data from the previous section. We’ll do both the one-sample, and the two-sample case. This means that we can use the likelihoods that we defined in the previous section, and we just need to add the priors.
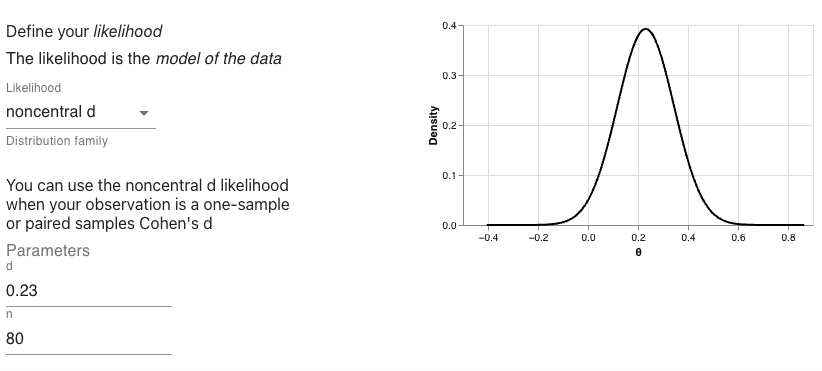
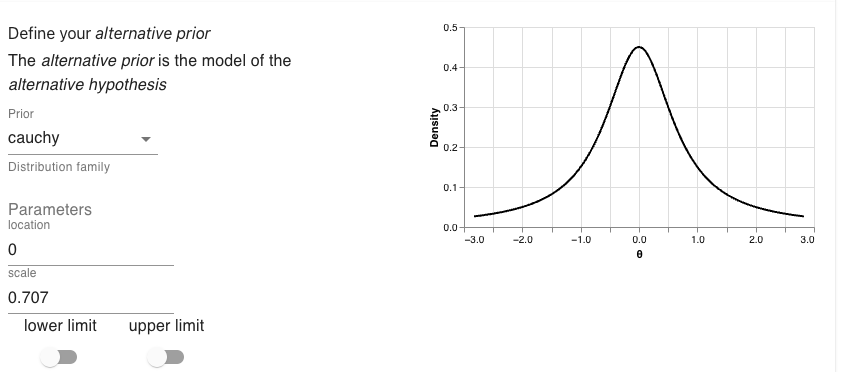
In the first one sample case, we found a d of 0.23 with a sample size of 80. For our alternative hypothesis, we’ll use the narrower Cauchy distribution. That is, a Cauchy with a location of 0 and a scale of 0.707. And for the null hypothesis we’ll use a point at 0.
I’ll use the bayesplay web-app to define the model. The setting’s are just as follows.
First the likelihood:
Then the alternative prior:
And then the null prior:
With these values entered, I can generate the R code. This code is shown below.
# define likelihood
data_model <- likelihood(family = "noncentral_d", d = 0.23, n = 80)
# define alternative prior
alt_prior <- prior(family = "cauchy", location = 0, scale = 0.707)
# define null prior
null_prior <- prior(family = "point", point = 0)
# weight likelihood by prior
m1 <- data_model * alt_prior
m0 <- data_model * null_prior
# take the intergal of each weighted likelihood
# and divide them
bf <- integral(m1) / integral(m0)
bf## 0.9064552And now we can give a bit of a description of our result.
The Bayes factor is 0.91. This means that the data are 0.91 times more likely under our alternative hypothesis relative to our null hypothesis.
With the one-sample case out of the way, we can now turn our attention to the two sample case. We’ll use the same priors as before, but now we’ll use the noncentral_d2 likelihood that we used to model this data in the previous section. Because we’re using the same priors as before, we can just update our likelihood from the previous chunk of code, and keep everything else the same. For this new likelihood, we’ll have a d of 0.99 and sample sizes of 13 and 12.
# define likelihood
data_model <- likelihood(
family = "noncentral_d2",
d = 0.99,
n1 = 13,
n2 = 12
)
# define alternative prior
alt_prior <- prior(family = "cauchy", location = 0, scale = 0.707)
# define null prior
null_prior <- prior(family = "point", point = 0)
# weight likelihood by prior
m1 <- data_model * alt_prior
m0 <- data_model * null_prior
# take the intergal of each weighted likelihood
# and divide them
bf <- integral(m1) / integral(m0)
bf## 2.976933And now a description of our result.
The Bayes factor is 2.98. This means that the data are 2.98 times more likely under our alternative hypothesis relative to our null hypothesis.
6.3 Interpreting our Bayes factors
Now that we have both Bayes factors let’s think a little bit about what they actually mean. What the Bayes factors did was compare two hypotheses. The first hypothesis (our null hypothesis) said that the effect size—that is, the difference in, for example, the accuracy of remembering words in the two conditions—was 0. The second hypothesis said that the effect size was not 0. But more specifically, it said the effect size was not 0 in the specific way as described by the specific Cauchy prior that we used.
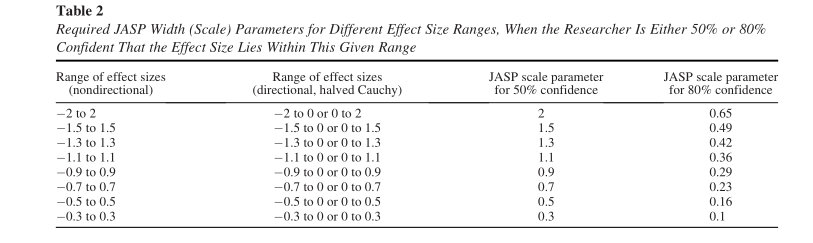
This Cauchy prior says that we think that if there is an effect, that it is probably somewhere between about -2.2 and 2.2 (that is, 80% of the prior distribution lies between these values. Schmalz et al, 2021 provides a handy table that tells you the 50% and 80% bounds for Cauchy priors of different scales (labelled JASP scale factor on the table).
However, if you’re comfortable with R then you can work it out yourself.
For example, the code below calculates how much of the defined prior is
between -2 and 2.
# define the prior
p <- prior("cauchy", 0, .707)
# work out how much of it is between -2 and 2
integrate(Vectorize(p$prior_function), -2.2, 2.2)$value## [1] 0.8020498The Bayes factor calculation sets up two hypotheses about what we think about the effect size in the case that there is no effect (the null) and in the case that we think there is an effect (the alternative) and tells us under which of these two scenarios we’d be more likely to observe our data.
Note, however, that the two hypotheses that we compared are only two out of a possible infinite set of hypotheses. I might, for example, think that if there is an effect then it is not zero in a different way. I might, for example, think that if there is an effect then it will be greater then 0 in a specific way as described by my prior. That is, I might one to perform a one-sided test rather than a two-sided (or two-tailed in frequentist terms) test.
To do this, all I would need to do is update my prior. In the web-app I can do this by toggling the limit switches and setting the lower limit to 0. As you can see the Cauchy prior is now cut in half so that it only contains values greater than 0.
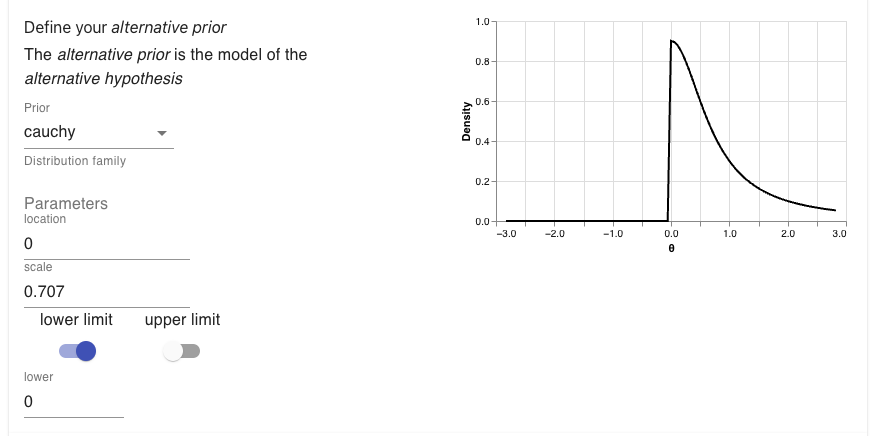
If we were to generate the R code, we’d see that the alternative prior
is now defined as follows:
# define alternative prior
alt_prior <- prior(
family = "cauchy",
location = 0,
scale = 0.707,
range = c(0, Inf)
)In fact, I could test any arbitrary sets of hypotheses I want. In the next section, on informed or subjective priors we’ll see how we can compare any arbitrary set of hypotheses we want.